目录
📚GrayLog查询语言
Graylog的查询语法接近Lucene语法。默认情况下,如果未指定要搜索的消息字段,则搜索中将包括所有消息字段。
📗官网文档
官方文档:https://docs.graylog.org/docs/query-language
以下内容总结了部分查询语法以及注意事项,如果不能满足日常使用,可以查看官网文档。
📘页面结构
GrayLog Search 页面结构
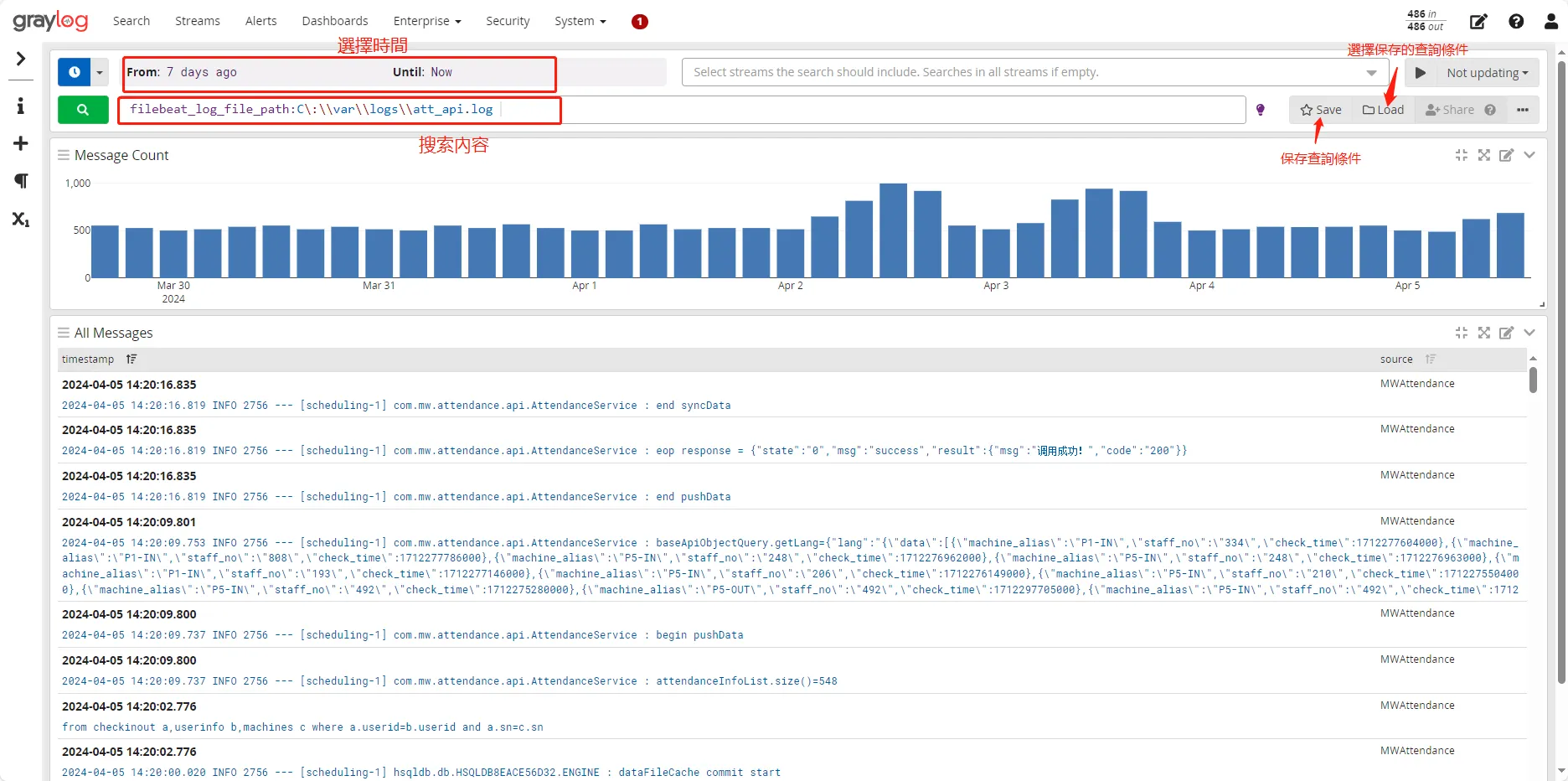
📍注意事项
❗️注意:
AND、OR 和 NOT 区分大小写,并且必须全部大写。关键词大小写敏感。检索内容大小写不敏感【取决于分词器】。
通配符:
-
?:匹配单个字段 -
*:匹配0个或多个字符 -
特殊字符查询需要使用
\转义:& | : \ / + - ! ( ) { } [ ] ^ " ~ * ?
⏰注意:
如果查询条件有特殊字符未转义,graylog会提示错误信息。
📜查询语法
💡字符查询
中文关键字会存在分词器问题。
模糊查询 直接输入关键词,多个词,用空格分隔【或的关系】 如果有且的关系,需要用AND 查询包含有SERVER_NAME或WorkSpace的数据
SERVER_NAME WorkSpace
模糊搜索(搜索类似的字段,容差大了会很慢)
xxx~ #默认容差为2(错两个字符也能搜出来) xxx~1 #设置容差为1(如果错误两个字符就搜不出来了)
精确查询 加引号
"SERVER_NAME" "WorkSpace"
字段查询 查询环境为dev的数据
env:dev
查询环境非dev的数据
NOT env:dev
查询不存在某个字段的日志
NOT _exists_:type
多字段查询
env:(local OR dev)
多条件查询
env:(local OR dev) AND source:host\-10\-0\-204\-66
正则匹配查询,默认导通配符是关闭的。也避免使用这种方式。
env:t?st AND full_message:api
特殊字符转义查询:& | : \ / + - ! ( ) { } [ ] ^ " ~ * ?
resource:\/posts\/45326
🗒数字字段
http_response_code:[500 TO *] #查询状态码在500以上的 包含500 http_response_code:[500 TO 504] #查询状态码在500 - 504 之间 包含 500 504 http_response_code:{400 TO 404} #查询状态码在400 - 404 之间 不包含 400 404 bytes:{0 TO 64] http_response_code:[0 TO 64} http_response_code:>400 http_response_code:<400 http_response_code:>=400 http_response_code:<=400 # 组合查询 http_response_code:(>=400 AND <500) # 日期范围查询 时间格式为:yyyy-MM-dd HH:mm:ss.SSS timestamp:["2022-11-12 04:31:50.693" TO "2022-11-12 06:31:50.693"] timestamp:[now-5h TO now-4h] #动态查询时间(h小时,d天)
📌常用查询示例
字段精准查询
格式:字段名:"查询信息"
示例:full_message:"告警信息"
注意
精准查询需要加引号。分词为默认分词器,对于中文默认为单字分词,不加引号查询就是模糊查询,一般不能达到预期效果。
例如:
检索【登录失败】关键字,如果查询条件为 【登录失败】,那么在使用默认分词器的情况下,会查询出来包含【登、录、失、败】这四个字的日志信息,如果查询条件为 【“登录失败”】可以精确查询到包含【登录失败】的日志信息。
组合多字段查询
示例:level_name:"INFO" AND full_message:"13788888888"
💡查询说明
graylog查询底层依旧是elasticsearch,检索不到跟分词器有关,默认是标准分词器。
例如:
消息内容如下,仅检索IOException会检索不到,检索java.io.IOException即可。
 elasticsearch内置分词器:
elasticsearch内置分词器:
- Standard Analyzer - 默认分词器,英文按单词词切分,并小写处理
- Simple Analyzer - 按照单词切分(符号被过滤), 小写处理
- Stop Analyzer - 小写处理,停用词过滤(the,a,is)
- Whitespace Analyzer - 按照空格切分,不转小写
- Keyword Analyzer - 不分词,直接将输入当作输出


本文作者:澳门🇲🇴上班的IT人
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!